
超星未来梁爽:软硬件协同优化,赋能AI 2.0新时代
近日,第三届清华大学汽车芯片设计及产业应用研讨会暨校友论坛在芜湖成功举行。作为本次活动的特邀嘉宾,超星未来联合创始人、CEO梁爽博士出席并发表主题演讲《软硬件协同优化,赋能AI 2.0新时代》。

大模型是AI 2.0时代的“蒸汽机”
AI+X应用落地及边缘计算将成为关键
自ChatGPT发布以来,大模型引爆“第四次工业革命”,成为AI 2.0时代的“蒸汽机”,驱动着千行百业智能化变革。保尔·芒图曾说:“蒸汽机并不创造大工业,但是它却为大工业提供了动力”,大模型也是如此,本身不会直接创造新的产业,而是与已有的行业应用场景及数据结合创造价值。
WAIC 2024落幕后,有媒体评论:大模型再无新玩家,AGI下半场是计算与应用。梁爽认为,AGI下半场将是AI+X应用落地和边缘计算。AI 1.0时代,服务器侧的神经网络模型,在安防、智能驾驶等应用领域里逐步下沉到边缘端,这一趋势也一定会在AI 2.0的时代再演绎一次,并且将在智慧城市、汽车、机器人、消费电子等领域创造出更为广阔的增量市场。
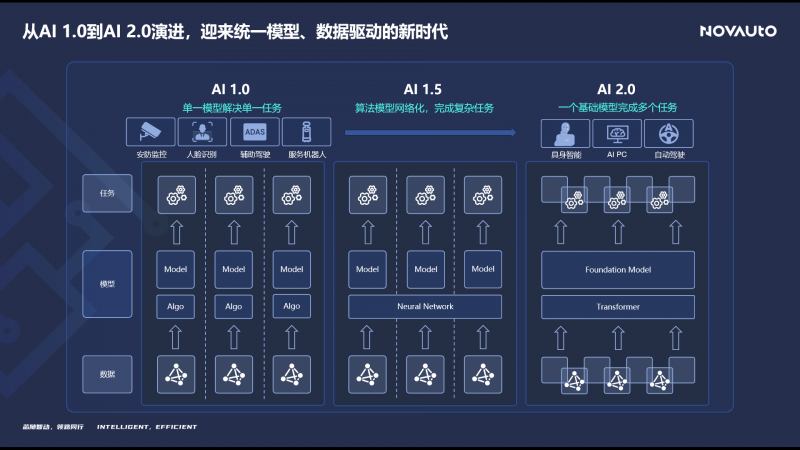
回顾AI的演进历史,可以看到,AI 1.0时代的主要模式是通过单一模型完成单一任务,例如安防、人脸识别、语音识别,以及基于感知-决策-控制分模块的智能辅助驾驶方案。梁爽认为,现在正进入一个“AI 1.5时代”,在智能驾驶、机器人等复杂系统中,统一用神经网络完成各个模块功能的实现,尽量减少人工规则,并通过数据驱动的范式提升性能,大幅降低人工处理各种长尾问题的难度。在AI 2.0时代,系统将由一个统一的通用基础大模型来应对多源数据输入,完成多种复杂任务,这一基础模型应该具备感知万物、知晓常识和理解推理的能力,智能驾驶、机器人的基础模型本质上是同一类基础模型。
端到端与大模型上车进行时
智能汽车是迈向通用机器人的必要阶段
近年来,智驾系统正在从传统的单传感器CNN感知,逐步升级到多传感器CNN BEV,基于Transformer的BEV和Occupancy方案,并正在向端到端大模型演进。随着规控部分逐步模型化,中间没有规则介入,因而在海量高质量数据驱动下,性能天花板会大幅提升,并大幅降低了应对长尾问题的人工参与度,使得软件工程量最多可下降99%。此外,视觉大模型的上车,帮助智驾系统进一步增加了对物理世界复杂语义的理解,使驾驶的行为更接近于人,提升了对未知场景的泛化处理能力。

梁爽指出,智能汽车将是未来迈向通用机器人的一个必要阶段,例如TESLA的Optimus机器人和智能汽车采用了同样的FSD平台,并且在系统配置、功能任务上相同。虽然两者的系统组成和迭代升级高度相似,但机器人的维度更高、任务更复杂,大模型下沉部署到边缘侧的设备里,形成一个“Robot-Brain”,会成为行业发展的关键。
大模型落地边缘侧存在较大挑战
软硬件协同优化是现实可行的落地路径
过去十年被称为AI加速器的黄金十年,CNN加速器的能效已经提升到了100TOPS/W级别。大模型的规模以及参数增长速度远超CNN时代,大幅超出了传统计算硬件的增长速度。而当前大模型的处理器能效仍小于1TOPS/W,与边缘侧应用需求存在两个数量级的差距,严重限制了大模型的落地。
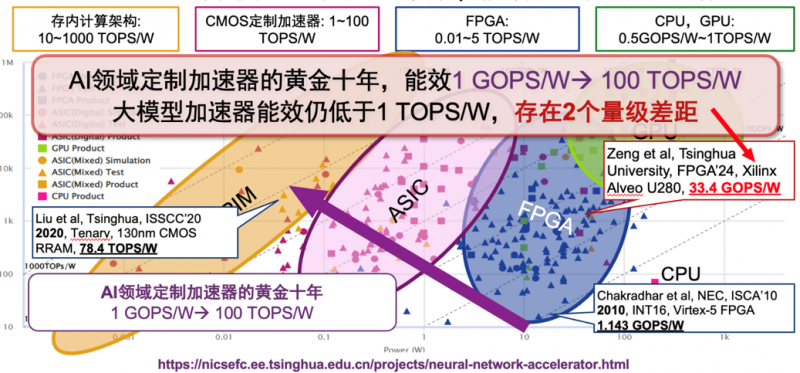
(摘选自汪玉教授发表于2024年1月的报告《端侧大模型推理,智能芯片的现状与展望》)
目前很多手机端本地部署的2B以内的“小”模型,在应用到边缘侧场景时,通常会出现历史信息遗忘等能力限制,而需求量更大、效果显著提升的7B量级以上的大模型,通常难以部署到现有的边缘侧芯片上,主要原因包括:(1)传统架构矩阵算力缺口明显,大模型中50-80%算力需求在Attention层中的各类矩阵计算,并且KV矩阵有明显稀疏性,需要专项支持;(2)大模型的参数量和带宽需求巨大,单7B级别的浮点模型就需要28GByte的存储空间,且权重的局域性比较低,所以大模型计算处理的过程需要频繁地对外存进行读取,每个Token的带宽需求都会大于10GB/s;(3)当前架构精度类型不足,计算精度传统的CNN网络通常可以用INT8实现较好的处理效果,而大模型中的各类算子会需要诸如INT4/FP8/BF16等不同精度的计算支持,并且像激活层、Norm层等的数据动态范围大,导致很多已有的量化算法也不能很好地支持。
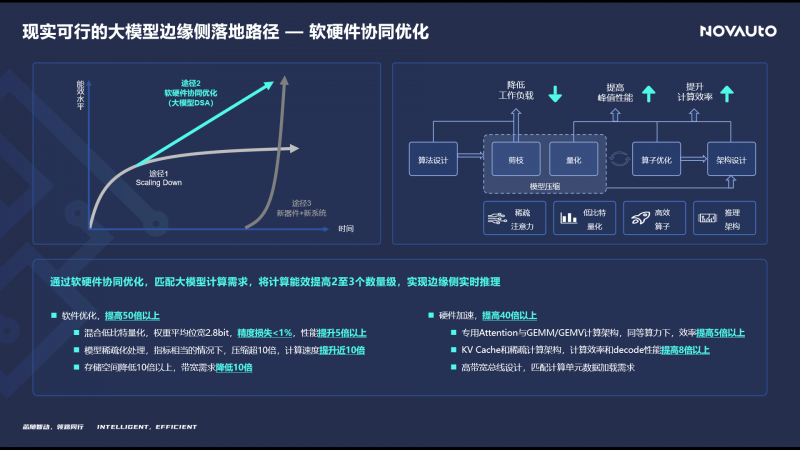
从提升大模型在边缘侧处理能效的方法来看,一种是通过提升工艺水平scaling down,但受摩尔定律和国际形势的影响,很难再继续持续;另一种是通过新器件和新系统,但应用的成熟度还有待技术上的进一步提升与完善。但在当下来看最为现实的实现手段,就是针对大模型应用来做软硬件协同优化,软件上通过新的混合量化方法以及稀疏化处理,硬件上则针对大模型中常见的算法结构进行加速设计,从而整体上实现2-3个数量级的能效提升。
针对大模型任务新需求深度优化
超星未来实现边缘侧AGI计算行业领先
超星未来主要面向各类边缘智能场景,提供以AI计算芯片为核心、软硬件协同的高能效计算方案,致力于成为边缘侧AGI计算的引领者。
「平湖/高峡」NPU:团队十年磨一剑,实现性能行业天花板
针对智能驾驶及大模型所需要的神经网络计算任务,超星未来自研了高性能AI处理核心「平湖」和「高峡」。「平湖」NPU主要针对以CNN和少量Transformer的感知类任务提供高效的计算,「高峡」NPU则是面向高阶智驾以及大模型的实时处理专门设计的加速核心。
其中「平湖」NPU针对主流CNN/Transformer模型的推理延迟以及帧率均为行业最领先水平,与某款市场上被广泛认可的竞品相比,单位算力的推理帧率在CNN任务上提高10倍,Transformer任务提高25倍。
「高峡」NPU架构采用了混合粒度的指令集设计,单Cluster可实现40TOPS算力,支持INT4/INT8/FP8/BF16多种不同计算精度,并且在内部缓存设计上做了优化设计,另外针对Sparse Attention和三维稀疏卷积,设计了专用的加速结构。通过这些优化设计,「高峡」NPU实现了对典型的生成式大模型的实时计算支持,LLaMA3-8B生成速度最高可达60tokens/s。此外,「高峡」NPU可以用相较NVIDIA Orin芯片1%的计算逻辑面积,来实现近乎等同的三维稀疏卷积处理速率。
「惊蛰」系列芯片:已于多领域批量落地,最新产品实现大模型边缘侧实时计算
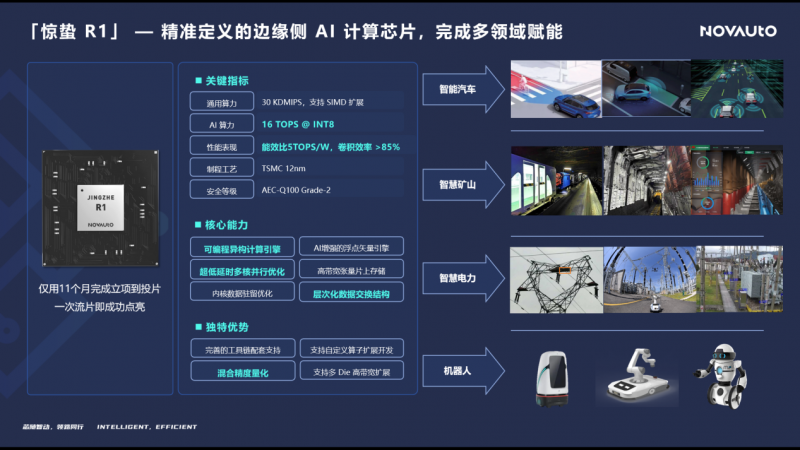
基于自研的NPU核心,超星未来在2022年底发布了边缘侧AI计算芯片「惊蛰R1」,NPU算力为16TOPS@INT8,典型功耗仅7-8W,从而可以支撑起各类系统方案的自然散热设计。「惊蛰R1」目前已在汽车、电力、煤矿以及机器人等领域实现了批量落地。
超星未来也即将发布「惊蛰」系列下一代芯片,可实现对大模型的实时处理,在12nm制程下将等同于骁龙8Gen3、天玑9300等SOTA手机芯片的处理效果。按照超星未来的芯片产品发展路径图,公司将继续保持产品矩阵的可扩展性,从边缘感知到智驾升级,逐步迈向“Robot-Brain”。
「鲁班」模型部署工具链:集成大模型优化新方法,软件协同实现40倍性能提升
在高效硬件架构的基础上,超星未来面向神经网络应用打造深度优化的「鲁班」工具链,可使边缘侧推理速度提高40倍以上,具体包括:
(1)业内领先的混合精度量化工具,支持PTQ/QAT/AWQ功能,支持INT4/INT8/FP8/BF16精度,量化损失小于1%;
(2)高效模型优化工具,支持敏感度分析、蒸馏、Lora,在精度损失小于1%的情况下,模型压缩率超10倍;
(3)高性能编译工具,提供丰富的计算图优化技术及面向异构核心的高效指令调度,推理效率可提高4-5倍以上。
特别针对大模型任务,「鲁班」通过特有的稀疏离群点保持和混合位宽量化的方法,可将权重位宽下探到平均2.8bit。基于稀疏掩膜的方法,可实现在模型处理能力相当的情况下,将LLaMA3-8B压缩90%以上,大幅缩减了模型的参数和计算量。
「仓颉」数据闭环平台:实现数据自动化生产,构建应用迭代闭环
在大模型时代,高质量算法迭代需要功能强大的数据闭环工具。因此超星未来打造了「仓颉」平台,包括数据管理、数据挖掘、数据增强、真值生产、模型生产和算法评测等功能,并且在多个环节都应用了大模型来提供功能上的增强。
基于该平台,通过构建完整流程,客户可以从环境中获取有效数据,并尽可能降低人工的参与程度,实现自动的数据挖掘和标注,从而助力客户实现数据驱动算法的迭代。目前「仓颉」平台已为车企、Tier1等客户提供了服务,同时也在延伸为机器人客户提供支持的能力。
脚踏实地,快步向前
为客户提供高效的“AI+”
基于团队在AI领域十余年的研发与实践经历,超星未来紧跟AI 1.0到AI 2.0的发展路径,不断打磨核心产品,实现AI+X应用落地。
在边缘侧场景,超星未来已在电力、煤矿等泛安防领域实现了芯片产品的批量落地,实现了规模化的营收回报,并通过落地,持续迭代产品相关生态,形成对智能驾驶与AGI等长周期方向的反哺。“在当前恶劣的市场环境下,实现快速的落地才是生存的王道。”

在智能驾驶场景,「惊蛰」系列芯片可支持多维智驾解决方案,如智能前视一体机、双目前视方案、5-7V高性价比行泊一体、11V1L高性能行泊一体等,并涵盖主流的行车、泊车以及智能驾驶和机器人通用的双目功能。相关产品的参考解决方案已基于实车完成了打通和工程优化。目前,超星未来已与某行业头部商用车OEM合作上车,同时与多家乘用车OEM客户达成业务合作,预计最早于2025年实现批量上车。
在边缘侧大模型推理场景,基于「鲁班」工具链的软硬件协同优化能力,超星未来最新芯片产品在验证平台上实测ChatGLM-6B可以达到超过15tokens/s的生成速度,10W量级的芯片即可支持高性能大模型的边缘落地;「高峡」NPU平台Stable Diffusion 1.5版本可以在3.5s内完成图片生成。基于以上能力,超星未来已与行业头部的机器人客户、大模型厂商等达成合作。
道阻且长,行则将至
共同构建AI 2.0新时代
“我们对技术发展的预估和意识通常是低估和滞后的,技术的发展一旦突破某个阈值,就会爆炸式地增长、覆盖,比如从ChatGPT的发布到现如今的‘千模大战’。不论是高阶的智能驾驶,还是通用机器人应用,只要技术范式是正确的,人员与资金持续投入,‘ChatGPT时刻’就一定会到来,而且这个时刻或许会比我们想象得来得更快。”梁爽表示,“超星未来期待与各位合作伙伴携手,从AI 1.0时代逐步迈进,共建AI 2.0的新时代。”
声明:本网转发此文章,旨在为读者提供更多信息资讯,所涉内容不构成投资、消费建议。文章事实如有疑问,请与有关方核实,文章观点非本网观点,仅供读者参考。





